



PayPayのInfrastructure Technology部 Cloud Infrastructure でTech Leadを務める西中です。
2023年4月20日と21日に、AWS Summitが開催されました。
2日間に渡って開催されたイベントは大盛況で、PayPayがAmazon Web Servicesを使用した事例の展示ブースには、計700名以上の方に足を運んでいただき、多くの来場者で賑わいました。今回のイベント用に作った限定グッズも大好評でした!
また、21日には、「PayPayにおけるマルチリージョン構成への取り組み」に登壇しました!
ご参加された方は振り返りに、残念ながらイベントへの参加が叶わなかった方は、こちらの記事で当日の様子を感じてみてください。

当日のプログラム
※当時の資料です
登壇でお話しした内容
PayPayのシステムの概要
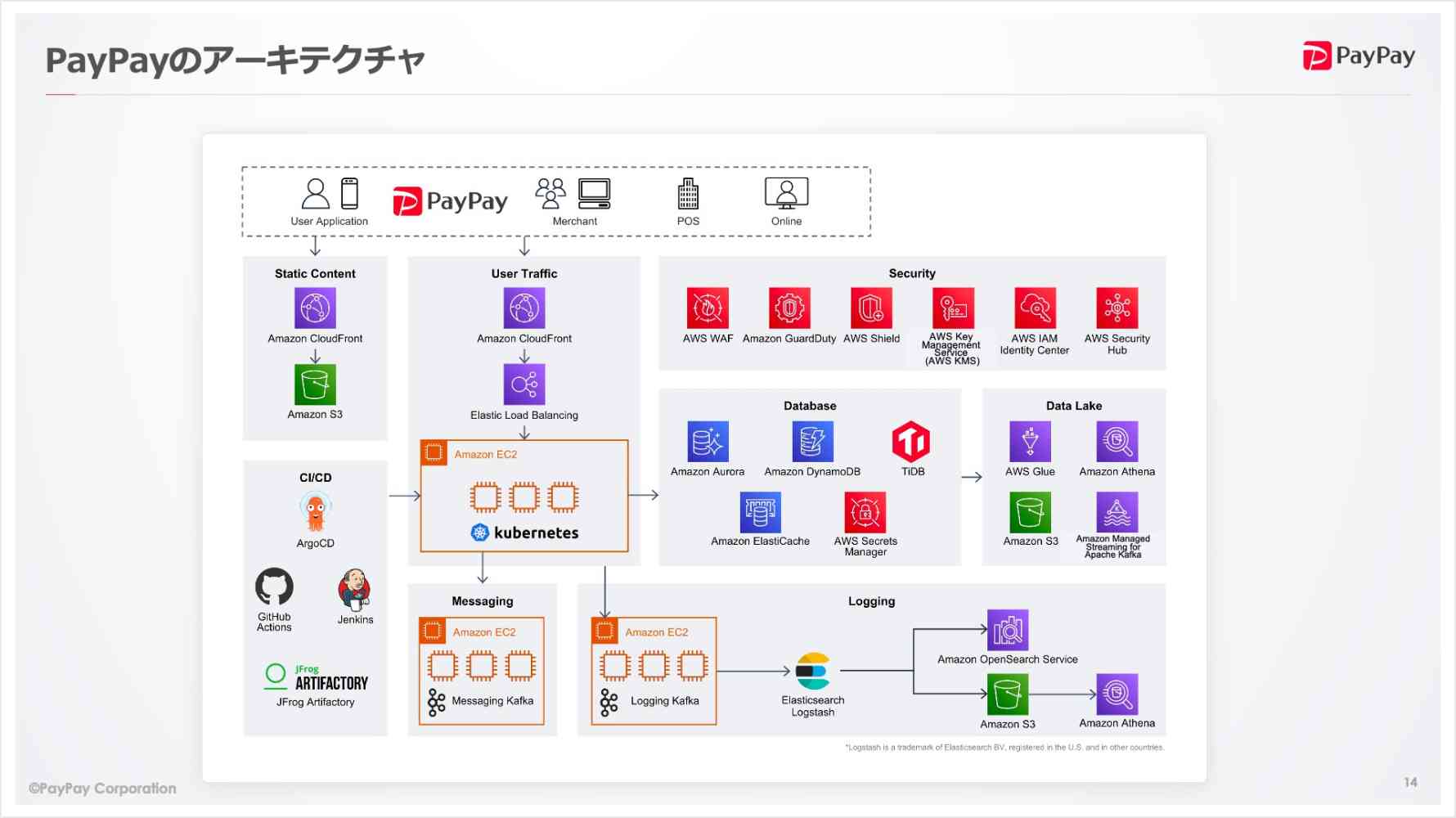
PayPayでは、サービスリリース当初よりAWSを活用し、ほぼすべてのシステムをAWS上で運用しています。PayPayのシステムにはいくつかの特徴があります。
- ほぼすべてのアプリケーションをKubernetes上で運用(独自でEC2上で構築)
- それらのアプリケーションはKafkaを利用し、非同期処理を実施(KafkaもEC2上で独自に構築)
- アプリケーションが利用しているデータソースは、DynamoDBやAurora、ElastiCache、TiDBなどを利用
- それらのデータを活用するために、Near-RealTimeのデータ基盤をGlueで構築
- Amazon OpenSearch Serviceでログのプラットフォームを構築
マルチリージョン間での課題
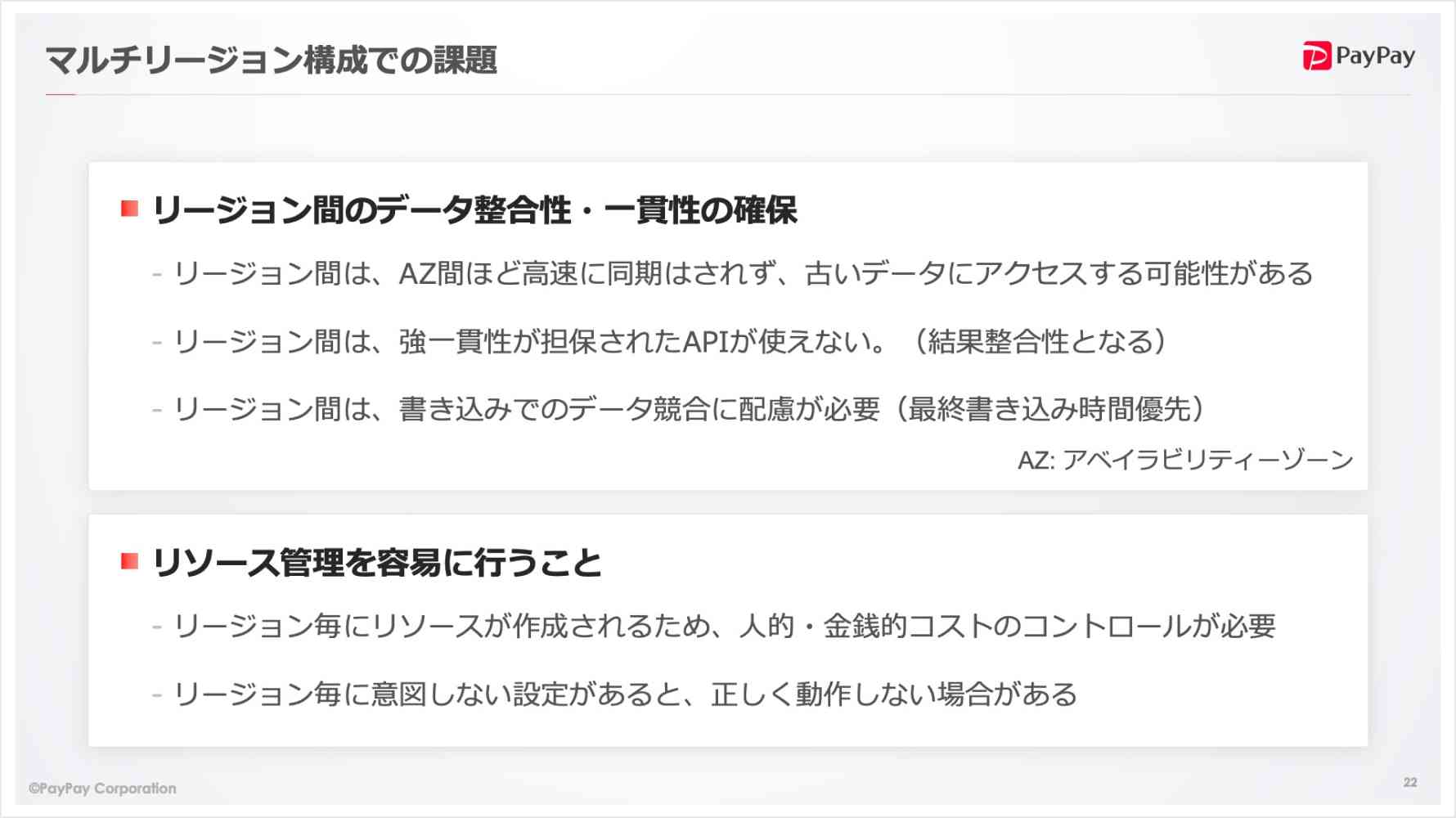
まずは、リージョン間のデータの整合性・一貫性の担保です。
- リージョン間は、AZ(アベイラビリティゾーン)間ほど高速に同期はされないため、古いデータにアクセスする可能性があります。
- リージョン間は強一貫性が担保されたAPIが使えません。例えば、DynamoDBのAPIは単一リージョンのみで結果整合性となります。
- リージョン間は書き込みでのデータ競合にも配慮が必要です。例えばS3でオブジェクトを書き込んだ場合、同じ名前の場合は最終確認時間が優先となります。
次に、リソース管理を容易に行うことが重要です。
- リージョンごとにリソースを作成することになるため、人的・金銭的コストのコントロールが必要です。単純に2つのリージョンにリソースを作成する場合、シングルリージョンに比べるとどうしてもコストや工数がかかることになります。
- また、リージョンごとに意図しない設定がある場合、正しく動作しない場合があります。
マルチリージョン構成でのTips
今回のセッションでは、Aurora、DynamoDB、KMS、Secrets Manager、S3の5つのAWSのマネージド型サービスについてのTipsを取り上げました。

PayPayでは東京リージョンにPrimary Cluster、大阪リージョンにSecondary Clusterとして、Global Databaseを構築しています。
- RDSで独自でbinlog replicationを組むよりも、Storage Layerで行われるため高速です。
- もし、東京リージョンのPrimary Clusterに問題があれば、大阪のSecondary Clusterを昇格させて書き込みに対応することが可能です。
- 昇格時には、remove-from-global-cluster APIを利用して大阪リージョンで完結できます。そのため、東京リージョン側にAPIが通らなくても対応できます。


- Global Tablesを活用することで、簡単にセットアップが可能です。
- 「強一貫性構成」「結果整合性構成」の2つの構成をとり、システムごとに書き込み先を分けて構築しています。(データ整合性の課題に対応)
- 巨大なTableやindexをレプリケーションする場合には要注意。同じTableやindexが他のリージョンに作られるため、バックアップの用途としてはコスト高になります。

- PayPayでは、マルチリージョンキーを利用して、システムの暗号化を安全にサポートしています。
- マルチリージョンキーは、キーの作成時にのみ対応可能。後からは変更不可です。
- シングルリージョンキーの場合には、暗号化のデータも含めた洗い替えが必要です。
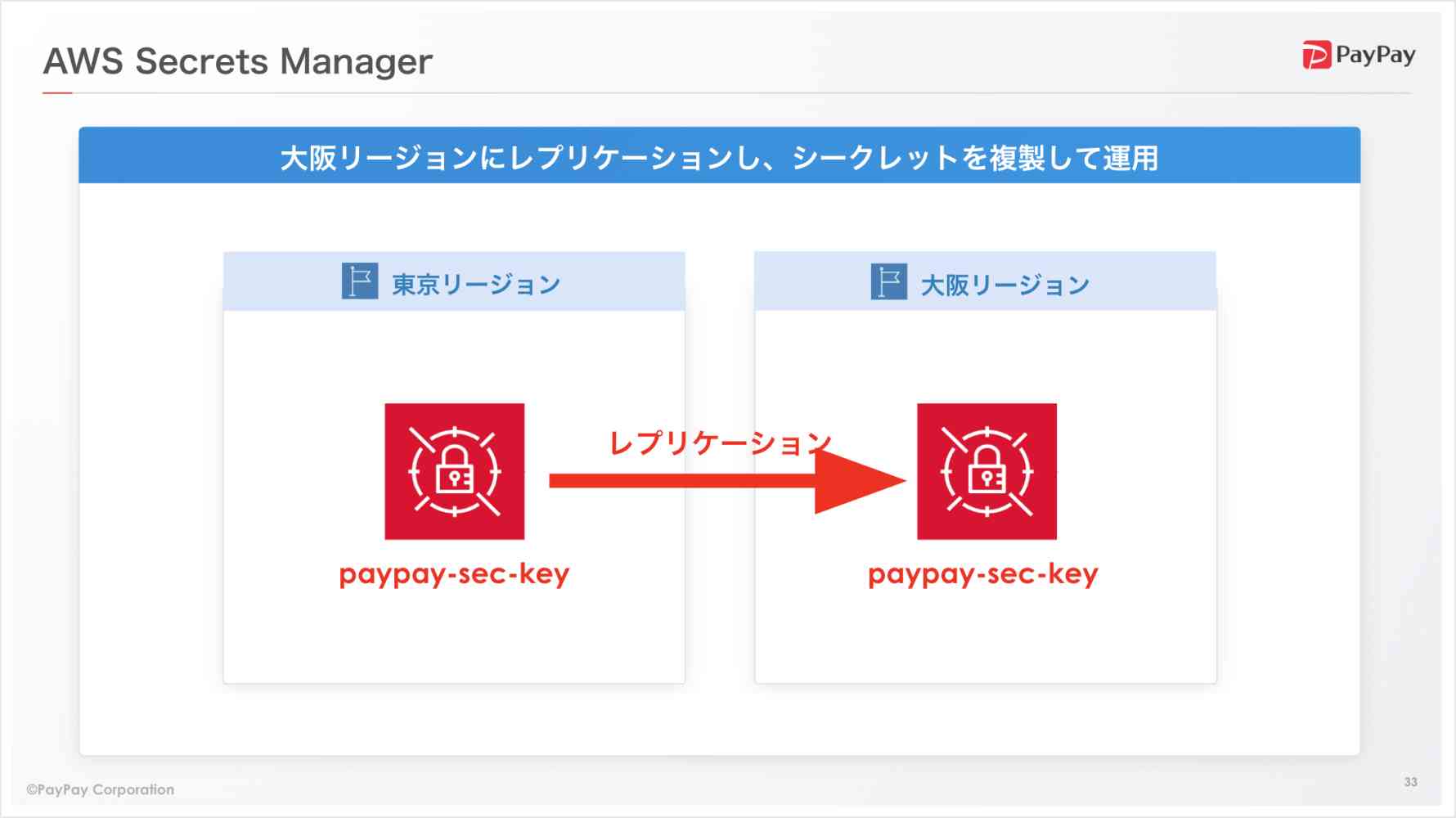
- Secrets Managerも同様に、レプリケーションで利用できます。
- KMSと異なり、事後でも設定可能です。
- 東京リージョンに問題があった場合でも、大阪リージョンからレプリカを昇格させてシークレット値の変更が可能です。
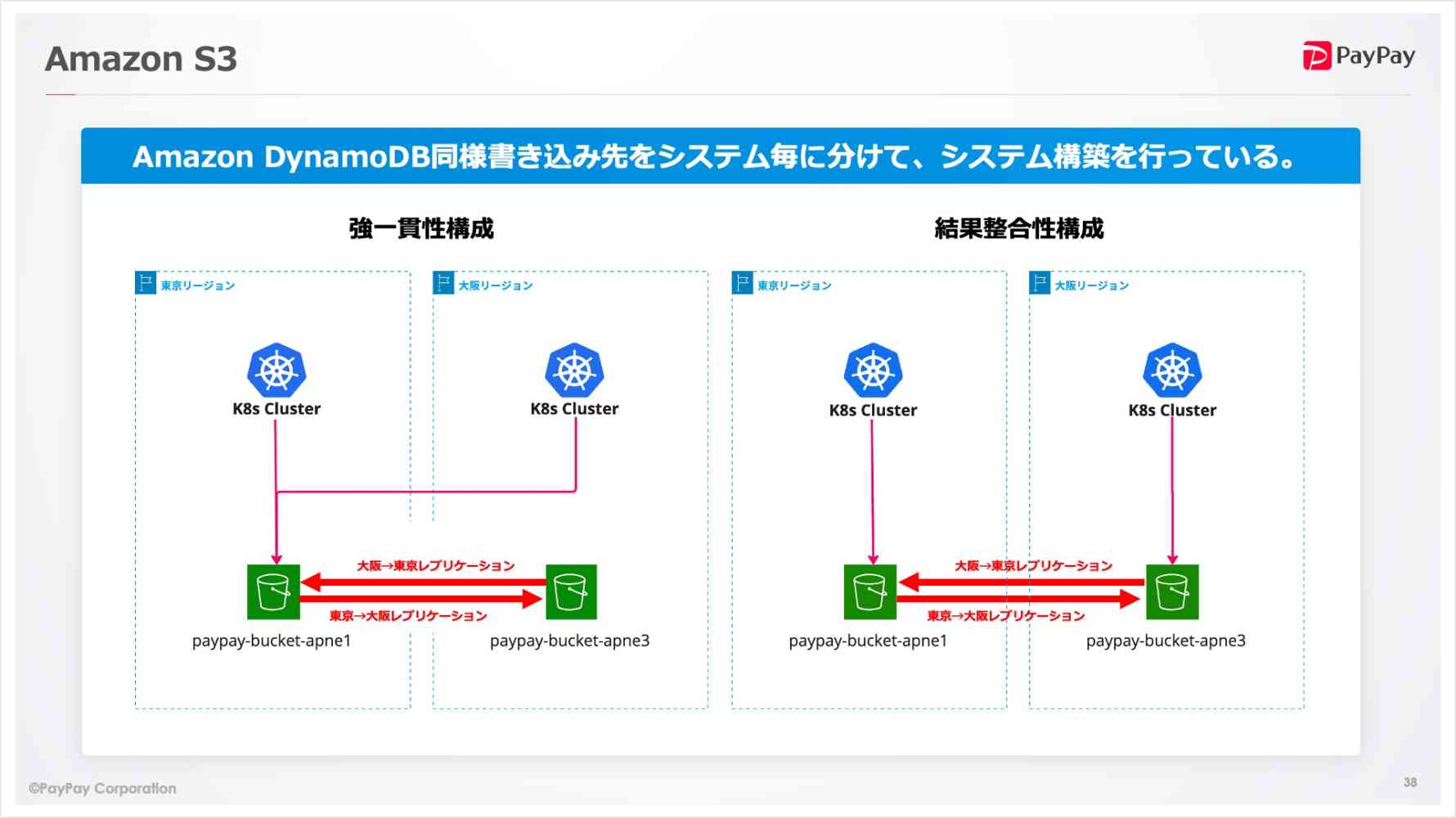
- PayPayでは東京リージョン、大阪リージョンで双方向にレプリケーションを作成したマルチリージョン構成です。
- DynamoDBと同様、システムごとに「強一貫性構成」「結果整合性構成」に分けて構築しています。
- ユーザーが画像をアップロードするのをトリガーに動くなどの場合には強一貫性構成としています。
- アプリケーションのコンフィグファイルなど、ラグが許容できる場合には結果整合性構成としています。
PayPayのS3におけるマルチリージョン構成の作り方

- 送信元と送信先のBucketを作成します。(今回は双方向のレプリケーションのため、お互いに送信元・送信先となる)
- 送信元・送信先のBucketにレプリケーションの権限を持ったIAM Roleを作成します。
- レプリケーションを作成します。
ただし、この設定では新規で書き込まれたObjectのみレプリケーションされ、既存のObjectはレプリケーションされません。
先ほどの設定のものに、既存のObjectをレプリケーションするBatch Operationsを適用するIAM Roleを作成することで、既存のObjectもレプリケーションされるようになります。
また、この2つのRoleはObjectに対する権限がない場合、レプリケーションができないので、Objectのオーナーの設定には注意が必要です。
マルチリージョン構成の管理

リージョン間のリソース管理を容易に行うには、権限やポリシーなどに一貫性を持たせて、作成する場合にもチーム全体で同じクオリティで作れたり、最終的にレビューもしやすいような状況を作ることが重要です。
ただ、厳密にすべてを作ると汎用性がなくなってしまいますので、名前やTag、その他の設定などについては自由度も残したいところです。
そこでPayPayでは、TerraformのModuleを使っています。
TerratformのModuleは、IaCであるTerratformにテンプレートを作成できる機能です。
例えば、外部公開するエンドポイントを作りたいということであれば、Route53、ALB、EC2といった構成をマルチリージョン構成で作成することができます。

また、インフラ以外でアプリケーション側と対応したこととしては以下の2点です。
- リージョンコードをアプリケーションソース内でハードコードしない
- 環境変数からリージョンコードやリソース名を呼び出すようにし、環境変数だけを変えることでリージョンごとのアプリケーションのリリースを容易になりました
- リソースごとに利用方法を確認し、アプリケーション側と共通認識を持つ
- 強一貫性が必要、結果整合性で問題ないなど、利用方法がマルチリージョン対応できるかをお互いに確認しております。
- その結果、IAM Roleを用い、利用方法毎に制御が可能となっています。
最後に、PayPayではさらなる可用性・拡張性を追求していきます。
現在利用しているKafkaやKubernetes、TiDBなどは、Raftに代表される分散を前提としたテクノロジーを利用しております。そのため、現在の構成にとどまらず、可能であれば国内の3rdリージョンまたは3rdロケーションなどを利用し、可用性を上げることを検討していきます。またサービスをより大きくするため、並行して拡張性の高いシステム構築に取り組んで参ります。

展示ブースの様子


ブースでのQ&A
- Q.PayPayのネットワークはどういった構成なのか?
- A.東京リージョンと大阪リージョンを利用し、各リージョンごとに3つのアベイラビリティーゾーン(AZ)を利用し、マルチリージョン、マルチアベイラビリティーゾーンでインフラを構築しています。
- Q.なぜEKSではなくて、EC2でk8sを利用しているのか
- A.2018年サービスをリリースする前、クラスタを最初に構築する際に、TokyoリージョンにEKSが来ていなかったためです。
- Q.なぜMSKではなくて、EC2でKafkaを利用しているのか
- A.2018年サービスをリリースする前、Kafkaの利用を開始した際に、TokyoリージョンにMSKが来ていなかったためです。
- Q.Data Storageとしていろいろな種類を利用しているが、どのように使い分けているか
- A.基本的には、Auroraを利用していますが、単純なkey-valueの様な値を利用する場合DynamoDBを選択するサービスもあります。また、パフォーマンスなどが課題となってくるようなサービスはTiDBを利用しています。
- Q.LoggingのためにOpenSearchとS3を利用しているが、どのように使い分けているか
- A.すべてのログは、S3に保存しています。直近のログのみ、検索性能を高めるため、OpenSearchを利用して、確認をしています。
- Q.Datalake周りの詳細はどうなっているか
- A.GlueでAuroraなどからデータを抽出して、Athenaでデータ確認ができるNear-RealTimeのデータ基盤を作ってます。データはS3に保存しています。
- Q.CICDに関して、AWSを利用していないのはなぜか
- A.
- CIでは、もともと、Jenkinsを利用経験者が多くいたため、Jenkinsを利用しているソースコード管理、マニフェストの管理として、GitHubを利用しているためGitHub Actionsを利用しやすかったため採用しています。
- CDでは、GitOPSベースでGitHub 上のmanifestへの変更をTriggerにKubernetesクラスタへのデプロイをしたかったためです。この部分は当時AWSが提供していた機能よりも、Argo CDの方が機能や導入の容易性などで優れていました。
- Q.User traffic のボックス内の CloudFrontは何の為に利用しているか
- A.Web系のTrafficは、S3とKubernetesにPathベースでトラフィックを分散させる必要があり、CloudFrontを使っています。
- Q.なぜPayPayがリリース当初からAWSを利用した・選んだのか。
- A.PayPayの早期ローンチを目指す中、初期のプロジェクトメンバーで利用実績があったのがAWSだったためです。

さいごに
今回のイベントでは、多くの方がPayPayの取り組みに興味を寄せていることを肌で感じることができました!
PayPayは50カ国を超えるメンバーとともに多様性のある組織で開発を行っています。誕生してまだ4年余りの会社だからこそのモダンな開発環境で、爆速で成長するPayPayならではの技術的課題とスケール感を味わうことができます。
組織の成長とともに個人の成長の機会も多いですし、なんといっても5,700万ユーザーに提供している価値と社会に与えるインパクトは非常に大きいものとなっています。
そんな環境で、今後も開発者の皆さんと一緒に、ユーザーにさらなる価値を提供していきたいと思っています!
現在募集中のポジション
※募集状況、社員の所属等は取材当時のものです。