



Hello! I’m Nishinaka, Tech Lead of Cloud Infrastructure in PayPay’s Infrastructure Technology Department.
The AWS Summit was held on April 20 and 21, 2023.
The two-day event was a great success and attracted a large number of visitors, with a total of more than 700 people visiting PayPay’s case study booth using Amazon Web Services. The limited edition merchandise made for this event was also very well received!
On the 21st, I gave a presentation on “Multi-Region Architecture” in PayPay.
For those who attended the event, I hope the article serves as a good retrospective, and for those who unfortunately couldn’t make it, let me try to give you a feel of what the atmosphere at the event was like!

Program of the day
*This is a document from that time.
The presentation
Overview of PayPay’s system
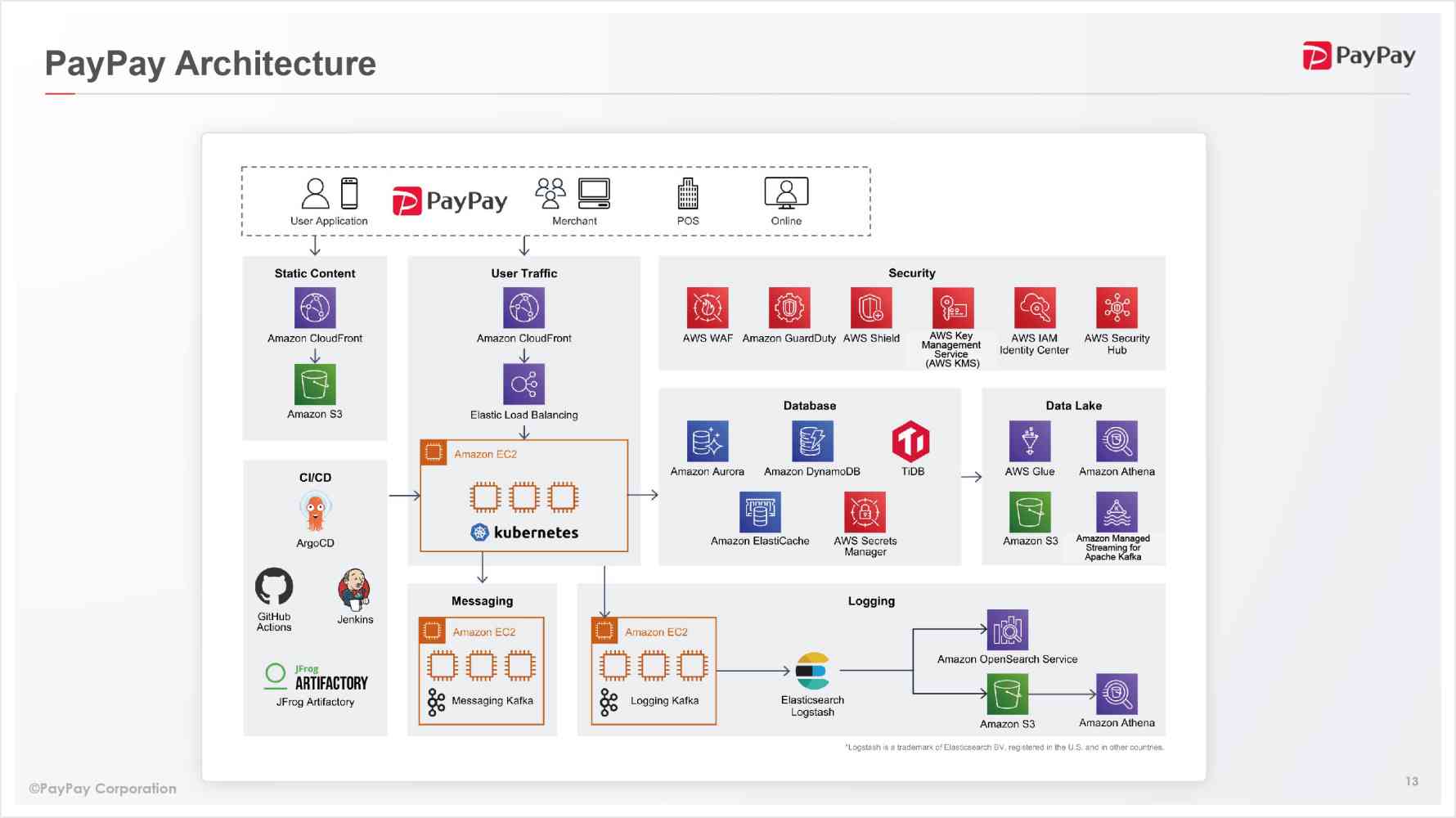
PayPay has used AWS since first releasing the service, with almost all systems operated on AWS. PayPay’s system is characteristic in a few ways.
- Almost all applications are run on Kubernetes (built independently on EC2).
- These applications use Kafka and perform asynchronous processing (Kafka is also built independently on EC2).
- Data sources used by the applications include DynamoDB, Aurora, ElastiCache, and TiDB.
- A near-real time data infrastructure is built with Glue to leverage the data.
- We have built a logging platform with Amazon OpenSearch Service.
Challenges of multi-regional environments

The first step is to ensure consistency and integrity of data across regions.
- Since synchronization between regions is not as fast as between AZs (Availability Zones), there is a possibility of accessing outdated data.
- APIs with strong consistency guarantees are not available between regions. For example, the DynamoDB APIs provide eventual consistency only in a single region.
- Data conflict must also be considered during write operations between regions. For example, if an object is written in S3 and has the same name, the final confirmation time takes precedence.
Secondly, it is important to facilitate resource management.
- Since resources are created for each region, human and financial costs must be controlled. Simply creating resources in two regions will inevitably require more cost and man-hours than a single region.
- Also, if there are unintended settings for each region, it may not work properly.
Tips for Multi-Region Architectures
This session covered tips on five AWS managed services: Aurora, DynamoDB, KMS, Secrets Manager, and S3.

PayPay has a Global Database with a Primary Cluster in the Tokyo Region and a Secondary Cluster in the Osaka Region.
- This is faster than a binlog replication in RDS because it is done in the Storage Layer.
- If there is a problem with the Primary Cluster in the Tokyo Region, the Secondary Cluster in Osaka can be promoted to handle write operations.
- During the promotion process, the remove-from-global-cluster API is used to complete the process in the Osaka Region. It can be handled even if the API does not pass through to the Tokyo Region side.

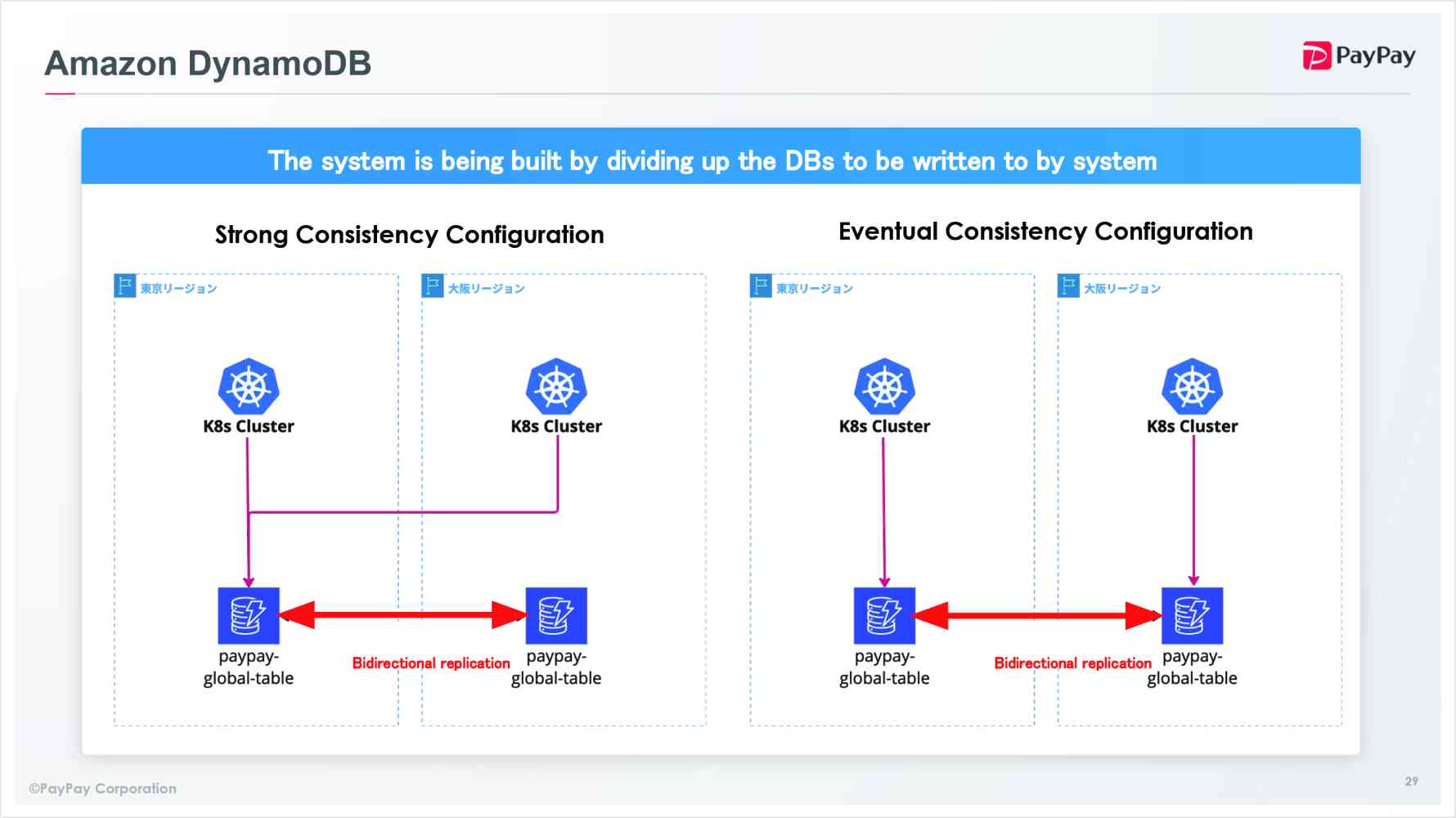
- It is enabled for an easy setup by utilizing Global Tables.
- The two configurations “Strong Consistency” and the “Eventual Consistency” are constructed by separating the write destination for each system. (Which addresses data integrity issues)
- Care is required when replicating huge tables or indexes. The same tables and indexes are created in the other region for backup purposes, which can become costly.

- PayPay uses a multi-region key to secure system encryption.
- Multi-region keys can only be supported at the time of key creation. They cannot be changed later.
- In the case of single-region keys, a complete data replacement is required including encrypted data.

- Secrets Manager is also used for replication.
- Unlike KMS, there is no problem even after the key creation.
- Even if there is a problem in the Tokyo Region, a replica can be used from the Osaka Region to change the secret value.

- PayPay has a multi-region architecture with replication in both directions in the Tokyo and Osaka regions.
- Like DynamoDB, each system is divided into “strong consistency configuration” and “eventual consistency configuration”.
- Strong consistency configuration is used when there are user-triggered actions, like image uploads.
- On the other hand, eventual consistency configuration is assumed to be used when lags are acceptable, such as in application config files.
- There is also a configuration that combines S3 and CloudFront.
- In this case, an Origin Group can be created in CloudFront and buckets added for both the Tokyo and Osaka regions.
- Then the traffic can be configured to be automatically directed to the Osaka bucket in the event of certain errors.
Multi-region architecture in S3 in PayPay’s case

- Create the source and destination buckets. (they will act as both the source and destination for two-way replication)
- Create an IAM Role with replication permissions for both the source and destination buckets.
- Create a replication
However only newly written objects are replicated and existing objects are not replicated with this setting.
By creating a separate IAM Role that applies butch operations for replicating existing objects to the one configured earlier, existing objects will also be replicated.
Also, these two roles cannot be replicated if they do not have permissions for the object, so care must be taken in setting the object owner.
Multi-region architecture management

In order to easily manage resources across regions, it is important to have consistency in permissions, policies, etc., and to create a situation where the entire team can create with the same quality and easily review the final product.
However, making everything too precisely will result in a loss of versatility, so it’s also important to leave some flexibility in terms of names, tags, and other settings.
That’s where PayPay uses the Terraform module.
The Terraform module is a feature that allows you to create templates within IaC using Terraform.
For example, if you want to create an externally accessible endpoint, you can create a multi-region architecture of Route53, ALB, and EC2.

Other than infrastructure, the following two points were addressed regarding the application side.
- Region codes are not hard-coded within the application source.
- This ensures that the region code and resource names are retrieved from environment variables, enabling easy release of the application for each region by simply changing the environment variables.
- Check the usage of each resource and have a common understanding with the application side.
- Confirm with each other that usage can be multi-region compatible, considering requirements such as strong consistency and no issues with eventual consistency.
- IAM Role can be used to control each usage method.
In conclusion, PayPay will pursue further availability and scalability.

Kafka, Kubernetes, and TiDB, which we currently use, are technologies that assume the distribution represented by Raft. Therefore, we are considering options to increase availability by utilizing a 3rd region or 3rd location in Japan, if possible, in addition to the existing configuration. In order to scale the service further, we are currently working on building highly scalable systems.

Exhibition booth


Q&A at the booth
- Q.What is the network configuration of PayPay
- A.We utilize the Tokyo and Osaka regions, with three availability zones (AZ) in each region, to build the infrastructure in a multi-region, multi-availability zone set up.
- Q.Why are you using k8s on EC2 instead of EKS?
- A.When we initially built the cluster prior to the service release in 2018, EKS was not available in the Tokyo region.
- Q.Why are you using Kafka on EC2 instead of MSK?
- A.When we started using Kafka before the service release in 2018, MSK was not available in the Tokyo region.
- Q.While using various types of data storage, how do you decide which one to use?
- A.In general, we use Aurora as the primary data storage. However we choose DynamoDB when using simple key-value-like data. In addition, services that face performance challenges are migrated to TiDB.
- Q.How do you distinguish between the usage of Opensearch and S3 for logging?
- A.We primarily use Opensearch and Kibana to check logs. As the amount of the log data has increased and cost has become an issue, we started archiving old logs to S3.
- Q.Could you provide details about the data lake?
- A.We have built a near-real time data infrastructure based on Glue that can extract data from Aurora and other sources and check the data with Athena. The data is stored in S3.
- Q.Why are you not using AWS for CICD?
- A.
- CI: Due to extensive experience with Jenkins among team members, we opted to utilize Jenkins for source code and manifest management through GitHub, which facilitated the adoption of GitHub Actions.
- CD: We wanted to deploy to a Kubernetes cluster with a GitOPS base to trigger changes to the manifest on GitHub. Argo CD was superior in this area in terms of features and ease of implementation to what AWS was offering at the time.
- Q.What is the user traffic box of CloudFront used for?
- A.To handle web traffic, we utilize CloudFront to distribute the traffic between S3 and k8s.
- Q.Why did PayPay choose to use AWS from the beginning?
- A.We had to launch PayPay quickly and the participating team members had previous experience with AWS, which led to its selection.

Lastly
During this event, we were able to see firsthand that many people are interested in what PayPay does!
PayPay develops its services in a diverse organization, collaborating with members from over 50 countries. As a relatively young company with just a little over four years of history, we benefit from a modern development environment that exposes us to the distinctive technical challenges and scalability that comes with PayPay’s rapid growth.
There are many opportunities for individual growth as well as organizational growth, and after all, the value we provide to 57 million users and the impact we have on society is very significant.
In such an environment, I would like to continue to work with developers to provide more value to users!
Current job openings
*Recruitment status and employee affiliations are correct at the time of the interview.